Stebalien's Blog
Hello, and welcome to my blog! I post sporadically on random subjects from Linux to Emacs. Check out my tags if you want to browse posts on a specific subject.
If you want to be notified about new posts, this blog has an Atom feed feed. However, unless you want to read my every rant, you may want to subscribe specific tags instead, each of which has its own Atom feed. Most feed readers will correctly deduplicate entries so you shouldn’t run into any issues if you subscribe to multiple tags.
Replacing Git-Link with Forge
I recently learned that, as of v0.4.7, Forge’s forge-copy-url-at-point-as-kill command works on files and regions (like git-link). That is, when visiting a file inside a git repo, forge-copy-url-at-point-as-kill will copy a (web) link to the current file if the region isn’t active and will copy a permalink to the selected lines if the region is active. This completely replaces the git-link package for me.
Even better, because it’s a part of the Magit family:
- It can copy links to commits in Magit’s blame buffers, log buffers, etc.
- When visiting a file at a specific commit (e.g., by pressing RET on a diff hunk or a Magit blame section), it copies links at the commit in question.
- It works in Magit status buffers, etc.
The downside is that it doesn’t integrate with VC, but if you’re using Magit that’s not going to be an issue for you.
Email actions in Emacs (notmuch)
A few years ago I wrote microdata.el, an Emacs package for extracting and acting on microdata in email. Since then, I’ve been using it daily to open Discourse and GitHub PR/issue notifications from notmuch with a single keypress (C-c C-c) instead of having to find and click on the appropriate link.
Many automated emails include structured metadata using either JSON-LD and/or Microdata. Adoption isn’t great, but code forges like GitLab and GitHub use this to include metadata in their notifications indicating how to view the associated issue/PR/etc. in the browser.
This package provides commands for reading and acting on this metadata.
Configuration
You can install the package with the built-in use-package-vc (or straight, or Elpaca, etc.). I’ve never bothered to publish the package to MELPA so you’ll need to directly fetch it via git.
(use-package microdata
:vc (:url "https://github.com/Stebalien/microdata.el"))
I distribute a notmuch integration library along with the package. However, there’s no reason it wouldn’t work with mu4e or Gnus (but you’ll have to write that integration yourself).
For notmuch, you can set it up like this (assuming you already have the microdata package itself):
(use-package notmuch-microdata
:bind
(:map notmuch-show-mode-map
"C-c C-c" 'notmuch-microdata-show-action-view
:map notmuch-search-mode-map
"C-c C-c" 'notmuch-microdata-search-action-view))
With this configuration, pressing C-c C-c in the notmuch search view or when viewing an email will open the default action URL (typically the issue, PR, or forum thread) in your browser.
Matching GMail
Unfortunately, this package will never be able to compete with GMail’s built-in actions feature. Given recent advances in language models, applications like GMail simply read the email itself so there’s little pressure for senders to standardize on structured metadata in standard formats.
Dim Unfocused Minibuffer Prompts
Update: Emacs 31 will ship with a similar feature to the one described below called
minibuffer-nonselected-mode.
I can easily tell if an Emacs buffer is focused by looking at the buffer’s mode-line. On the other hand, the only indicator that the minibuffer is focused or not is the cursor, and that’s pretty easy to miss.
I wanted to avoid making any intrusive changes to the minibuffer, so I decided to style the prompt based on whether the minibuffer is focused. When not focused, I remap the minibuffer prompt face to shadow.
Focused:
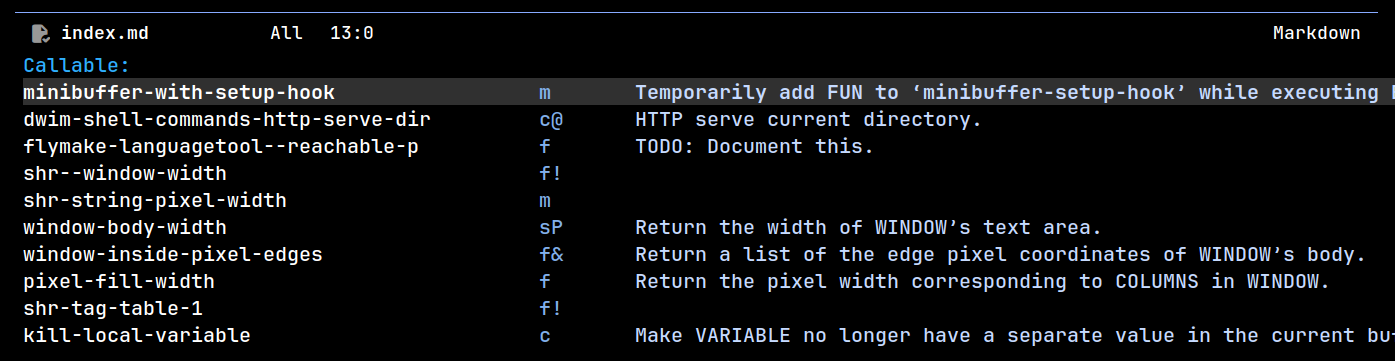
Unfocused:
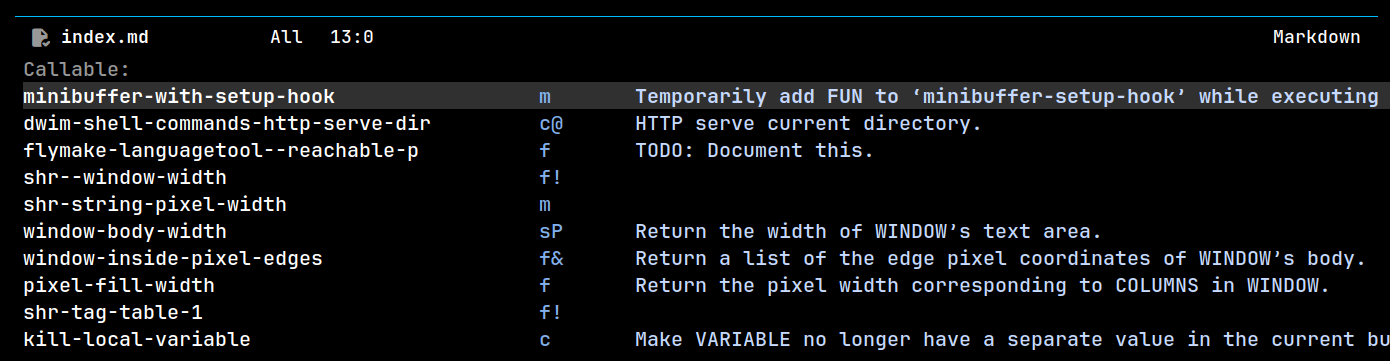
The code is pretty simple:
(defvar-local steb/focused-minibuffer-face-remap nil
"Face-remapping for a dimmed-minibuffer prompt.")
(defun steb/focused-minibuffer-update (w)
(when (eq w (minibuffer-window))
(when steb/focused-minibuffer-face-remap
(face-remap-remove-relative steb/focused-minibuffer-face-remap)
(setq steb/focused-minibuffer-face-remap nil))
(unless (eq w (selected-window))
(with-selected-window (minibuffer-window)
(setq steb/focused-minibuffer-face-remap
(face-remap-add-relative 'minibuffer-prompt 'shadow))))))
(defun steb/minibuffer-setup-focus-indicator ()
(add-hook 'window-state-change-functions 'steb/focused-minibuffer-update nil t))
(add-hook 'minibuffer-setup-hook #'steb/minibuffer-setup-focus-indicator)
My approach was heavily inspired by this Emacs Stack Exchange answer, but I tried to simplify the implementation and make the styling a bit less intrusive.
Grammar Tools in Emacs
Up till now the only prose checker/linter I’ve used in Emacs is jinx. It’s an amazing spell checker for programmers and technical writers: it handles snake_case and CamelCase symbols, knows what to spell-check based on the text’s face, etc. Unfortunately, it’s just a spell checker and won’t catch any grammatical errors.
Now I’m looking for a local (offline) grammar checker. Something to catch stupid mistakes: repeat words, cut off sentences, tense disagreements, homonyms, etc. I tend to jump around a lot when writing and want a tool that’ll tell me when I started a sentence in one tense and finished it in another, or failed to finish it entirely. Ideally the tool would also provide general writing advice — wording improvements, etc. — but I’ll probably need a full language model for that.
Vale
I first tried Vale because it’s by far the simplest option and has great support for markup languages and can even lint prose within source code. To be honest, it looks like a great choice for teams that want custom rule-based prose linting. Its primary power is the expressivity of its rules allowing organizations to set and enforce writing standards (e.g., “don’t start a sentence with ‘but’”). Unfortunately, it’s not a general-purpose grammar checker, and I’m not trying to conform to some specific set of writing stylistic rules.
However, if that’s what you want, vale has great Emacs integration via flymake-vale. I say great because (a) it uses flymake (no language server setup required) and (b) only checks changed text making it very fast and lightweight.
Harper
Next I tried Harper. Like Vale, it’s mostly rule-based. However, it’s more focused on providing general-purpose writing tips than on enforcing specific stylistic rules: it can catch repeat words and tell me when a sentence is too long; it has some very basic grammar rules and can catch article/noun disagreements (a/an); it even has some rules to catch “it’s” versus “its”. I hate it.
- Harper thinks “given its computed value” should be “given it’s computed value”.
- Harper won’t catch errors like “Go to a the park.”
- Harper likes to harp on “mistakes” like “long” sentences.
Harper is like that middle-school english teacher with their highly rigid rules about writing: great for teaching good habits to the notice writer but, at this point, I’ve ingrained them. When I break these rules, it’s (usually) because I meant to break them.
What I need is a tool to help me catch stupid errors and/or a tool to help improve the flow of my writing. Harper is not that tool.
Worse, the only Emacs integration I found was harper-ls, a language server. In Emacs specifically, this has a few downsides:
- Eglot (the default language server package in Emacs) only supports a single language server per buffer, so I can’t use Harper along with some other language server.
- Eglot expects Language Servers to be used in “projects” and will enumerate all project files when it starts the language server. Starting a language server in my home directory takes forever as it tries to enumerate all my files (including my backup snapshots…).
- Eglot will start one language server per project (in this case, often per directory).
However, if you really want to use Harper, you can trick Eglot into treating all documents (with the same major mode) managed by harper as if they were in the same project. If you don’t care, skip to the next section.
First you’ll need to define a new project type for harper. In my case, I “root” the project in a guaranteed empty directory.
(cl-defmethod project-root ((project (eql harper)))
"/var/empty")
(cl-defmethod project-name ((project (eql harper)))
"harper")
This virtual “harper” project contains all files managed by the harper language server. Honestly, it’s probably OK to simply return nil here.
(cl-defmethod project-files ((project (eql harper)))
(when-let* ((server (cl-find-if #'eglot--languageId
(gethash (eglot--current-project)
eglot--servers-by-project))))
(mapcar #'buffer-file-name (eglot--managed-buffers server))))
Finally, add a project “finder” function that puts all buffers that would be managed by harper into the “harper” project, if and only if we’re acting on behalf of Eglot (eglot-lsp-context is non-nil).
(defun project-try-harper (dir)
(and eglot-lsp-context
(string= (cadr (eglot--lookup-mode major-mode)) "harper-ls")
'harper))
(add-to-list 'project-find-functions #'project-try-harper)
LanguageTool
Finally, I broke down and set up LanguageTool: it’s by far the most advanced free-software grammar tool. The next step-up is Grammarly and/or LanguageTool’s online offering, but I absolutely refuse to use a remote grammar tool (I’m not sending all my notes, etc. to someone else’s server).
Unfortunately, it’s definitely a heavyweight. It uses at least 2.5GiB of memory, and you’ll need the 14GiB n-gram database if you really want it to do its job. On the other hand, it’s leagues beyond Harper and Vale in terms of catching grammatical mistakes.
In terms of Emacs integration, I ended up creating a fork of flymake-languagetool that has improved performance (avoids re-checking the entire document on change); excludes markup, code, etc. before sending text to LanguageTool instead of filtering errors afterward for improved accuracy/performance; and renders diagnostics in the correct location even when Emoji are present in the buffer. I considered using a language server, but I had enough of that with Harper.
I recommend you find a good LanguageTool docker container or something because setting it up from scratch isn’t a fun exercise. However, if you’re like me and (a) use Arch Linux and (b) avoid sketchy docker containers, read on.
On Arch, I installed the languagetool package from the extra repository (pick jre21-openjdk-headless when prompted), along with a few AUR packages: languagetool-ngrams-en, fasttext, and fasttext-langid-models. The fasttext packages are only used for language detection so they should be optional, but LanguageTool’s HTTP server complains if they’re not installed.
Next, you’ll need to create a configuration file to tell LanguageTool where to find everything:
fasttextModel=/usr/share/fasttext/lid.176.bin
fasttextBinary=/usr/bin/fasttext
languageModel=/usr/share/ngrams
You’ll need to pass --config /path/to/my/config.properties to the languagetool command (which you can configure via flymake-languagetool-server-command and flymake-languagetool-server-args:
(setopt flymake-languagetool-server-command "languagetool"
flymake-languagetool-server-args
'("--http" "--allow-origin" "*"
"--config" "/path/to/my/config.properties"))
That’ll get you a basic functioning LanguageTool server.
Taming Org-Mode With Side Windows
Org-mode will, occasionally, pop up a window that takes over half the screen. Specifically, this happens to when:
- Capturing a note (
org-capture): I get a half-screen window asking me to select the capture template. - Inserting a timestamp (
org-timestamp): The calendar takes over half the screen (assumingorg-read-date-popup-calendaris non-nil).
This is especially annoying in the second case because the calendar window invariably covers the window I’m referencing while taking notes. That is, I usually take notes with the following setup where the red window is the selected window and the gray window is some document I’m referencing.

In this case, attempting to insert a timestamp in my notes causes a calendar window to pop-up, covering the reference window:

The solution is to use side windows. E.g., I can put the calendar at the top of the screen above the notes/reference windows, replacing neither.

First, put calendar windows in a dedicated side-window at the top of the screen.
(setf (alist-get (rx bos "*Calendar*" eos) display-buffer-alist nil nil #'equal)
'(display-buffer-in-side-window (side . top) (dedicated . t)
(window-height . fit-window-to-buffer)))
Then, put org-capture template selection buffers in a side-window at the bottom of the screen, instead of taking over half the screen.
(setf (alist-get (rx bos "*Org Select* eos) display-buffer-alist #nil nil 'equal)
'(display-buffer-in-side-window (dedicated . t)))
If you want to better understand Emacs window management, I highly recommend Mickey’s (of Mastering Emacs) excellent write up: Demystifying Emacs’s Window Manager.
Executable Org-Mode Files
My Emacs config lives in a massive org-mode file and I often want to re-tangle from outside Emacs (because, e.g., I broke my Emacs session for some reason). I could just use a simple Makefile, but that’s no fun. Instead, I’ve turned my config into a self-tangling script by adding the following two lines to the top of my init.org file and marking it as executable:
#!/usr/bin/env -S sh -c 'emacs --batch --eval="(setq org-confirm-babel-evaluate nil)" --file "$0" -f org-babel-tangle'
# -*- mode: org; lexical-binding: t -*-
Now I can run ./init.org in my ~/.emacs.d directory and my config will tangle itself into the correct files.
This might sound like a weird gimmick – to be honest, it kind of is – but I’ve been tangling my config this way for years at this point and it “just works” with no dependencies other than Emacs.
A similar trick can be used to execute all org-babel blocks in an org-mode file, making org-mode a viable meta-scripting language for tying together scripts written in different languages – even scripts executing across multiple machines via TRAMP.
#!/usr/bin/env -S sh -c 'emacs --batch --eval="(setq org-confirm-babel-evaluate nil)" --file "$0" -f org-babel-execute-buffer'
# -*- mode: org; lexical-binding: t -*-
#+TITLE: Hello World
#+BEGIN_SRC elisp
(message "Hello World!")
#+END_SRC
Letters From A Maintainer
This blog post is a series of letters from me, an OSS maintainer, to anyone contributing code to OSS projects. My goal is condense haphazard advice into a single document and help contributors understand a maintainer’s perspective on OSS.
Read more...Fix For Lenovo X1 Carbon Not Charging
I recently made the mistake of plugging my Lenovo X1 Carbon (Gen 5) into a 5 volt USB-C charger overnight. The LED on the side indicated that it was charging but, when I woke up in the morning, it obviously hadn’t. Worse, it now refused to charge even when plugged into the correct charger.
The fix is simple (although undocumented as far as I can tell). Basically, you need to reset the battery as follows:
- Unplug from any power sources (this won’t work if you don’t do this).
- Reboot into the BIOS setup (F1 on boot).
- Navigate to the Power menu.
- Select the “Disable built-in battery” option.
- Wait for the laptop to power off and then wait 30 seconds.
- Connect the power and start the laptop.
This will temporarily disable the battery which seems to reset any “bad charger” bits.
Hopefully, this will save others some time and frustration.
The X1 Carbon is otherwise a great laptop with an awesome keyboard. However, because this is my blog and I can rant all I want here:
- The dedicated Ethernet port is pretty much useless given the ubiquity of USB-C. I’d have much preferred an additional USB or USB-C port.
- The nipple seems a bit firmer than the one on my X220 and also seems to get into the “wandering cursor” state a bit more frequently.
DRACL (thesis)
So, I never actually posted this and I figure someone out there may be interested… For my masters thesis, I designed (but never got a chance to implement) a decentralized (well, federated), privacy preserving, access control protocol. The purpose of this post is not to explain DRACL but to get you interested enough to download my thesis and take a quick look.
The primary contributions are:
First, an exploration of the privacy, security, usability, reliability, and performance trade offs involved in designing an such an access control protocol. We explore topics like,
- Account recovery versus security: no completely trusted third parties.
- Privacy versus efficiency: e.g., choosing to not update something reveals that it hasn’t changed.
- Security versus efficiency: cached credentials, etc.
- Ease of integration: no new services, no server-side network requests, no account management, etc.
- Ease of use: groups, no surprises, etc.
etc.
Second, an interesting (not-yet-peer-reviewed-but-probably-mostly-correct-and-definitely-interesting) zero-knowledge (ish) set intersection protocol. We use this protocol to construct “keys” and “ACLs” such that the keys opaquely encode the set groups in which the user is a member and the ACLs opaquely encode the set of groups that have access to a particular piece of content. By opaquely, I mean that neither party learns anything about the sets that their keys encode (except what they learn through running the protocol, see below).
Given a key that intersects with an ACL, a user can prove that the key intersects:
- Without either party learning anything other than the cardinality of the intersection (the user/prover learns this).
- Without revealing any user/prover-identifying information to the website/challenger other than the fact that the user’s key intersects with the ACL being proven against.
Furthermore, we can expire keys after a period of time (and even allow semi-trusted third parties to “renew” these keys without granting these parties access to the protected content).
There are quite a few interesting features/guarantees that are hard to sum up succinctly so I recommend you try skimming the thesis. It goes through a lot of trouble to try to explain DRACL in an approachable manner.
The primary downsides are:
- Complexity. We designed the system to be simple from a usability standpoint but, under the covers, the actual logic, protocol, and crypto is complex.
- Size limitations. No user in this system can feasibly have more than 1000 or so friends/groups of friends at a time.
- Expensive crypto. Not “expensive crypto” from a cryptographers standpoint but expensive crypto from a systems engineers standpoint. Authenticating can take multiple seconds of CPU time.
Stash
Stash is a library for efficiently storing maps of keys to values when one doesn’t care what the keys are but wants blazing fast O(1) insertions, deletions, and lookups.
Use cases include file descriptor tables, session tables, or MIO context tables.
See the project page for more.